Background
While at a masonic Jazz club in 2022, I was having a heated debate with a close friend regarding the risk and conveniences of operating a technology business in the cloud. My central defense was the typical talking points: delegation of responsibilities, ease of scaling, immediate access to multiple availability zones, ability to hire candidates with domain expertise… ultimately all selling points you’ve already heard. While his was simple: when another company owns the infrastructure you depend on, they can also strip it away overnight if they’d like… it’s a liability.

While both present valid points, they also exist as different use cases in a company’s lifespan. More often than not, the first few years of market fit require rapid exploration with less incentive for large upfront capital and time investments. As the company matures, less work may be done that requires substantial architectural changes, while the focus becomes on testing, ensuring uptime SLAs, and redundancy. It’s worth noting that after this friend exited his company, he started a farm and dug a hole in the ground to place his phone while not in use – it was the Overton window in full effect.
Now the optimistic perspective above is oftentimes far from reality. Within the Ephemeral Task and Market Research industry, it’s far more likely that test coverage is never done, multi-region or multi-zone cloud designs are rarely implemented, and the lock-in effect is deferred, as an industry overzealous with Mergers and Acquisitions by Private Equity treats the cloud as a feature, as it allows entire platforms to be migrated by simply handing off an AWS account to a new parent organization.
After that original discussion, I walked away with a new perspective of risk and servitude. We also started to consider edge cases that were becoming more prevalent in daily operations: inode exhaustion, intra-VPC latency between nodes, Heap-Only Tuple configuration and extensions on RDS, bloom filter support in ElastiCache until Redis 8… the list started to grow. Yes, there is always a solution by spending more money; but with each step there is also a continued platform debt that builds inertia, slowly handicapping technological creativity.
Project development meetings started to include feasibility discussions on how to implement features within the context of cloud-specific services, and not in the reliable but boring way which can still scale just as easily. In parallel, our AWS spend had breached $40,000 per month and reserved pricing 3-year terms were coming up for replacement.
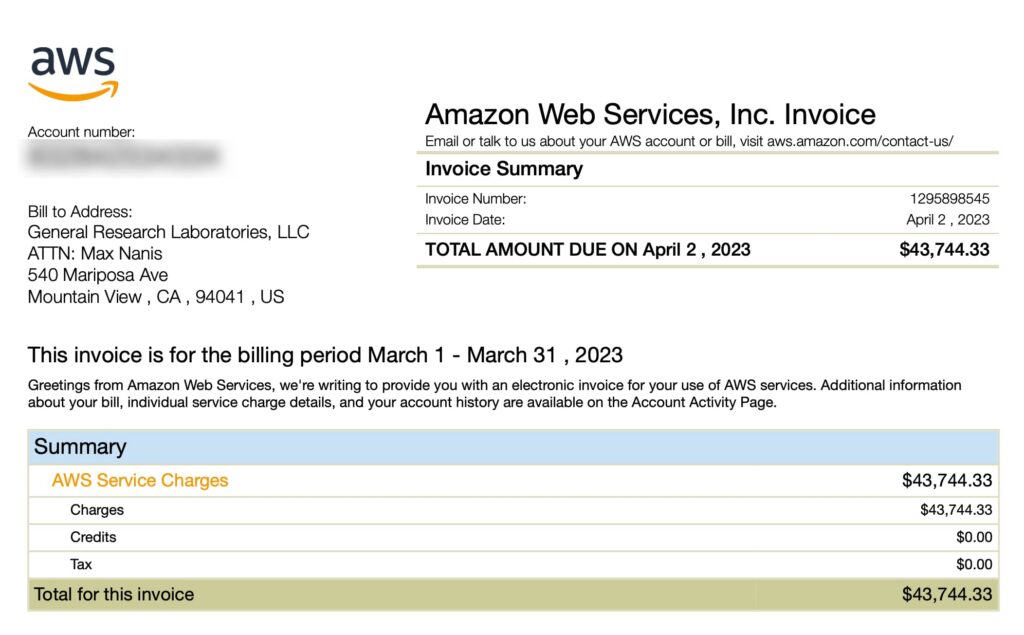
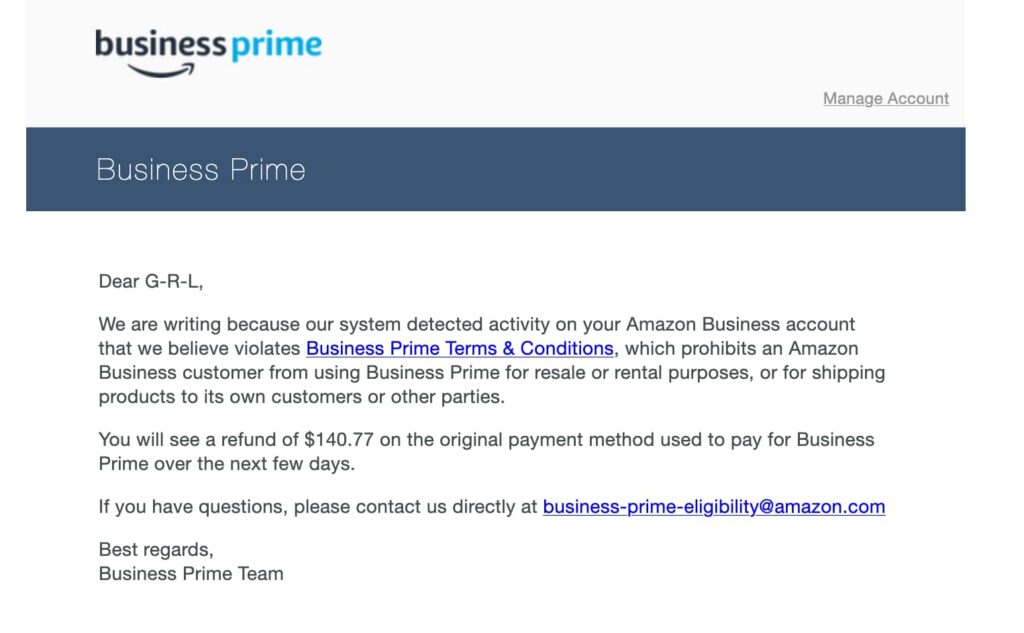
I was saturating the annualized 5% points-back limit from our American Express Amazon Business Prime Card until tragedy struck: our Business Prime membership was canceled without notice. I’m assuming it was due to redeeming all the points for Airbnb and Booking.com stays (gift cards are viewed as high-risk or a resold item). An Amazon script was making decisions with no real human involved and absolutely no way to resolve the issue. Even with assistance from an AWS Sr. Program Manager getting involved to no avail, it was clear we’d be shit out of luck in an actual emergency.
The Rulebook
While there is a rich homelab community of enthusiasts online, they often take shortcuts and don’t face any of the real challenges of migrating a business from an active hyperscaler to an on-prem or datacenter infrastructure. Likewise, there are stories from people who compare a VPS from Hetzner or OVH running their database to the costs of their Amazon multi-zoned or multi-region RDS, but at a fraction of the cost.
If you wish to make an apple pie from scratch, you must first invent the universe.
When starting from zero, even the process of making a sandwich takes months. The challenge was straightforward: migrate off AWS without operationally compromising any features. The ongoing acceptable expenses would be (1) Electricity, (2) IP Transit, and (3) Cabinet or Cage rental at a facility. This was a fair compromise with my friend, as I don’t have the upfront capital to start a power plant, his boat is ill-equipped to circumnavigate the world and trench Corning RocketRibbon, and facility rental includes layered physical security exceeding what I could otherwise provide. The primary goal for these unavoidable ongoing costs is the ability to relocate and bring online new locations with as little overhead as possible.
Given the challenge of operating an EUV lithography machine, it would be acceptable to purchase upfront and annualized equipment with a simple caveat: no tier-1 OEM server vendors (Dell, HP, Lenovo) could be used. Likewise, exercise as much vendor diversity as possible and maintain component tracking and fallback systems for every SKU in production. Two is one, and one is none.
As a final requirement, no 3rd party could be used to manage or operate anything, and an internal bus factor of 2 is required for any individual part of our technical operations. While in the middle of this process, Railway proclaimed “So You Want to Build Your Own Data Center” while not only failing to build their own facility, but (and I quote) “to install it properly, we bring in professionals,” in which they rely on Direct Line Global to manage their locations.
Upon the Dawn of Opportunity
You must classify facilities into distinct categories, as datacenters are not only buildings with a bunch of computers inside, but purpose-built and oftentimes designed for specific uses. Recent news is saturated with stories of rapid expansion projects to fuel rising AI use, and generally speaking, these AI facilities can be further away from telecommunication hubs as the focus is on energy cost and water cooling requirements. The time delay of sending light over fiber optic cables out to these facilities in order to communicate with your favorite AI tool is insignificant relative to the amount of time it takes for them to come up with a non sequitur response. Another category is referred to as single-tenant hyperscaler facilities. These are where a single company like Amazon (AWS), Microsoft (Azure), or Google (GCP) uses the facility exclusively to serve their cloud customer needs. This has a feedback loop effect, where as more businesses move into a facility the latency of communication between those companies also goes down. Take a drive around Loudoun County 1 and you’ll see for yourself. As a center point of ARPA and MAE-East (an early Internet Exchange point), the region quickly grew to host these cloud companies.
Another category of datacenter is referred to as Network and Carrier-Neutral Exchange facilities. Think about the monthly internet service you pay for at home: there needs to be a small piece of glass thinner than a human hair, all converging at a single point in some facility for your ISP to manage their customers. These facilities should be able to house all your phone and internet companies, an internet exchange point, and likely even a copy of YouTube 2. A favorite of mine comes from the history of 111 Eighth Avenue, a Port Authority building from the 1930s that resulted in the largest real-estate deal of 2010, where Google purchased the building for $1.8 billion 3. The previous owners, Taconic Partners, had spent over 20 years bringing in technology and telecommunication companies, which helped shape the fiber optic paths of the East Coast. Take a quick look at its roof, absolutely littered with generators. Sure it’s hipster to have your employees next to Chelsea Market, but it’s cooler to have a massive fuel tank underground that can run the entire building for over 10 days off the grid 4 and is one of the most connected buildings on the East Coast, alongside 60 Hudson Street. I digress…


Our thesis is that the consolidation towards hyperscalers has driven down the price of Network and Carrier-Neutral Exchange facilities. Many of the technology businesses that used to operate in these facilities have since transitioned towards the convenience of hyperscalers, and the talent and skill set to manage these facilities are becoming more difficult to recruit. Furthermore, as server compute density has dramatically increased over the past 5 years, the consolidation of rack space in these facilities due to technological improvements has also freed up additional space.
These are the types of locations that we want to operate in because they’re extremely low latency and house Internet Exchange Points. System tools like traceroute allow us to analyze not only where our users are coming from, but what paths they’re taking to get to our servers. Geographical locations should be chosen in a manner that will result in the fastest API services for our users by ultimately placing our application servers closer to them. It’s a pity to be constrained by the speed of light. While not accounting for initial installation and setup costs, a reasonable estimate is that a cabinet in any part of the world can be rented for at or less than $2,500 per month, which typically will include some amount of base electricity like 1.5 kVA. The amount of compute that can now fit within a 42-unit cabinet is difficult to comprehend; it was certainly an order of magnitude greater than any of our existing paid services at AWS. I’d venture to guess that the entirety of the Ephemeral Task and Market Research industry could co-exist in a single rack.
Popcorn & Silicon Chips
Advanced Micro Devices (AMD) debuted the EPYC Milan 7003 series of server CPUs in 2021. By March of that year, you could have 64 cores at 225W for $7,060 5. Going back to the challenge at hand, it was decided that I would never purchase brand-new equipment on release. It was far too attractive to wait at least N-1 release cycles. As sure as the sun will shine, AMD released the EPYC Bergamo 9754 as part of the 9004 Series in 2023 where you could have 128 cores at 360W for $10,631. The critical issue here is those prices are only if you buy 1,000 at a time, so the real incentive for buying one release cycle behind is a matter of necessity. As predicted, General Research received our first EPYC 7713 CPUs for $5,109.91 each in 2023 and the challenge quickly got underway.


From our projections, it should have been possible to operate our entire cloud workload on two of these chips at a time. Now that would be bad, because when one breaks, I would lose sleep. However, the other issue with buying these chips is that it’s remarkably difficult to purchase server equipment in a reliable way. Typical consumer supply chains don’t exist, and our needs are minuscule compared to those of a hyperscaler. Thankfully, we’ve formed a great relationship with ASA Computers, where I can text my rep any SKU and he tells me the price, if it’s in a US facility, or how long it’ll take to come over from Taiwan.
In the theme of the challenge, I can’t operate in full compliance with the Berry Amendment, nor would I want to as a globally operational company. Therefore vendor diversity also covers procurement, and in addition to ASA, we’ve since spent two tortuous weeks trying to secure delivery from NeweggBusiness, have ordered second-hand from eBay, set up with Supermicro’s eStore, and have even bought directly from liquidation sales… one of the benefits of living in Mountain View, CA.
While a risk emerges by not using a tier-1 OEM server vendor that can use predictive failure monitoring as part of a paid support agreement, our thesis is simple: buy more warm and cold spares. As the price of equipment continues to plummet relative to the cost of hyperscalers, the value add simply isn’t there for our use case. To mitigate this risk, we run Netbox and track every single SKU in our infrastructure and follow a simple rule: keep N × 2 resources available to us (so as to never exceed 50% utilization), and then an additional cold spare of anything either already racked and unplugged, or if it’s an internal component – it stays binned in a Pelican case at the bottom of a cabinet. I don’t really know what I’m doing, but this seems like a reasonable safety net and everyone can sleep peacefully at night.

It’s also worth noting that every component has its own quirks and features regarding procurement. For example, it’s much more difficult to acquire Kioxia drives directly without feeling like you’re getting hosed, which then leads us to purchase low-hour S.M.A.R.T. metric NVMe drives second-hand from eBay. At the same time, I can just go to the Solidigm store on Amazon and buy a D7-P5620 online 6. While the irony isn’t lost on me, I’ve made sure to use our Amazon Business account’s remaining Amazon points to purchase as much equipment as possible to help the migration off AWS.
For other parts like network cards, fiber optic cables, and transceivers, other suppliers such as fs.com (from Shenzhen, China) have been used. No matter what, all purchasing decisions are logged and tracked to ensure replacement. While subject to future coverage, preventing fiber optic vendor lock-in is the primary concern.
As an extra-curricular activity, I would like to expand our host diversity to use Clearwater Forest chips from Intel Fab 52 in Chandler, Arizona when they become available 7. More immediately, there is no technical limitation for incorporating the AmpereOne platform today. A final goal of having three different vendor platforms would be nice, but comes with significant operational, research, implementation, and maintenance overhead.
Anitya & Governance
The world is unstable. I don’t trust any regime. I want full autonomy.
Lest you think I exaggerate, AWS ME-CENTRAL-1 and ME-SOUTH-1 got struck by fucking missiles last week (I believe more specifically it was a HESA Shahed 136 in Bahrain) 8, but whatever. These facilities are increasingly target-rich environments, and often sit vulnerable without anti-aircraft defense systems.
At around 4:30 AM PST, one of our Availability Zones (mec1-az2) was impacted by objects that struck the data center, creating sparks and fire. The fire department shut off power to the facility and generators as they worked to put out the fire. 9
The reason is simple: it’s cheaper and easier to maintain two locations in different parts of the world that hopefully don’t get bombed at the same time, and then rely on the elegance and resilience of the Border Gateway Protocol. The issue is that getting (1) Electricity, (2) IP Transit, and (3) Cabinets with that mentality is easier said than done. At a very high level, we want to host a cabinet with the full ability to move operations onto and off of it remotely once it is online.
Given that we have users that hit our APIs from all around the world, it would be nice to operate in three distinct geographical regions. We started the transition with a US and European location, primarily because it was easiest to live within driving distance of a fiber-dense facility, and Munich to simplify some GDPR processing requirements. However, we’ve already vetted a location in SE Asia and Djibouti, locations which both serve as critical submarine cable hubs.
IP addresses are not real and everything is a mirage.
Future networking posts will cover this subject in more detail, but I would like to operate while maintaining relationships with a diversity of Regional Internet Registries (RIRs). We’re trying to acquire block space in an ethical manner, with the goal of an IPv4 and IPv6 block from at least three RIRs. The neo-colonialist Lu Heng 10 has set an extractivist policy that General Research does not want to fund, as he openly exploits African IP space. Purchasing clean IPv4 block space will be allowed, and we’re currently on the ARIN IPv4 waiting list.
A humble abode
Selecting a datacenter is more complicated than just finding an ideal geographical location, as you’re essentially selecting a landlord. They’re private companies and you must act in accordance with their own terms of service. When evaluating options for us, I look at Tier-1 ISPs and Internet Exchanges in the facility. However, other considerations are used, like the financial stability 11 of their operations, floor weight loads, power grid sources, days of fuel autonomy, physical security, and more. Less obvious factors I’ve learned to account for are loading dock access, shipping and receiving procedures, and whether there is a parent lease on the building (common for subdivided buildings in urban centers). We’re a small team, and knowing I can have deliveries arrive and be held until all the parts for an installation are there before I fly into a city and install is critical. Likewise, being able to keep cold spare parts on standby at the facility ready to be swapped or installed by smart hands in an emergency provides a lot of reassurance.
The two biggest players are Equinix and Digital Realty. To satisfy the challenge with my friend, the goal is to lease physical space from three distinct datacenter REITs. We’ve proudly based our main location with Hurricane Electric for all of the reasons above, but also for their IPv6 network and their controversial stance towards protecting minorities and disabled individuals from organized violence 12.
Plug in and breathe out
Networking was the most difficult part of migrating off of the cloud and has remained the most important, full stop. I ran OpenWRT when it came out, would wardrive with my friends as soon as I got a license… that doesn’t mean I knew how to start or run an ISP 20 years later. The domains of expertise in the software engineering fields provide a remarkably distinct subset of skills from those of a network engineer. I want to personally thank Trimarchi Manuele for some extremely insightful conversations during this process; please hire him if you have any form of networking design and implementation challenges to work through.
The progression of today’s college student
is to jettison every interest except one.
And within that one, to continually narrow the focus,
learning more and more about less and less– Liz Coleman, A Call to Reinvent Liberal Arts Education
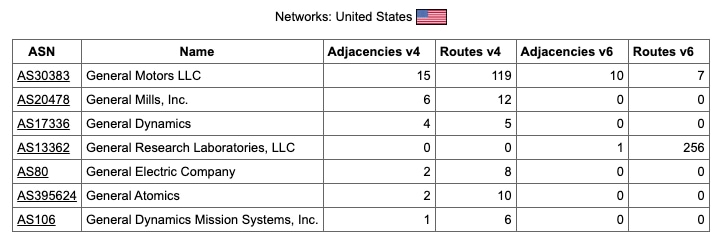
A cabinet or room in a datacenter can have multiple “WAN connections” going into it, except each is essentially a transit line to a different ISP. In our case, a singlemode fiber cable comes via a 1310nm SFP LC module. Then you start an eBGP session to advertise your IP address space out into the world. This is a separate concept from paying for the transit itself, and an organization must register with an RIR before doing so. For example, our Autonomous System Number is AS13362 and this allows us to acquire IP blocks that we advertise rather than getting them leased. Once you have peering set up, the craft of the network engineer becomes more of an art than a science. Inbound and outbound traffic levels can be monitored and routed in such a way as to find the path of least resistance. If the transition off the cloud is partial or done in steps, you can even make direct connections to hyperscalers 13.
Likewise, you’ll need to familiarize yourself with JunOS (Juniper / HPE), Cisco IOS, and RouterOS (MikroTik), then spend countless nights up figuring out why things don’t work as you test your network designs. The vendor lock-in and proprietary nature of networking equipment is sickening. Moving forward, we’ll cover any networking concepts largely in relation to the CCR2216-1G-12XS-2XQ, or whatever new flagship router MikroTik provides, as long as they continue to be free from vendor licensing requirements. These routers run a Marvell Prestera 98DX8525 Application-Specific Integrated Circuit (ASIC), and you can think of it as a CPU that is extremely good at routing network packets. They can retain the rules for how to move packets around so that some traffic can operate near the 100G line rate. Our decision in this field was that it would be cheaper and better in nearly every way to simply purchase multiple CCR2216-1G-12XS-2XQ units per location than to deal with any HPE or Cisco sales representatives.



Accountability without exception
The challenge stated clearly: no ongoing monthly expenses.
For most organizations, migrating from AWS to a VPS partner like Hetzner or OVH will likely continue to have a dependence on AWS Route 53 or Cloudflare’s authoritative nameservers. Therefore it was also required to set up our own authoritative nameservers running glue records. In line with our objective, the domains have a diversity of registrars to manage glue records and use multiple TLDs.
We also heavily leverage email not only internally, but for customer support for users taking surveys and doing work online. This means maintaining a robust email platform was required. To accomplish this we’re running an internal Postfix and Dovecot stack with load-balanced incoming and outgoing Proxmox Mail Gateway servers and highly configured rspamd Lua scripts and server-side sieve filters. This allows us infinite email addresses, storage, and advanced header tag analysis to better manage email usage. Also, it means Google and Microsoft can’t read our emails.
Hardened security comes without exception when going off the cloud, as every configuration file, open port, and system configuration becomes a liability. Whether it’s port knocking, honeypots, firewall configurations, resident security keys, network VLAN and VRF isolation practices, it was required to make no exceptions to protect customer data. However, from anecdotal experience, I could argue poorly designed cloud architectures are just as likely to be vulnerable.
As of March 2026, our only ongoing third-party service provider expense is with MaxMind and Slack. Both will be phased out by the end of the year.
The end justifies the means
What began as a challenge resulted in an extensive migration that ultimately taught us more than we had expected in such a short amount of time. Likewise, I believe that some McLuhanism exists in this exercise. The more engineers think within the confines of cloud hyperscalers, the more cloud hyperscalers inform engineers how to think. A new generation of developers is trained not to build what is right, but what is easy because there is a cloud service for it.
While I enjoy a good obsession, the denouement was saved for last. The reality of this series will help detail how most (but not all) of these efforts have provided General Research with some technological capabilities that will become invaluable to survive the next decade as the Market Research industry faces an existential crisis, as residential proxies and AI automation tools complete surveys to defraud buyers. The industry is antiquated and the extent of the most advanced security services in our space is easily spoofed and thinks RTT timing analysis and a WebSocket stream of DOM events are sufficient to identify adversaries.
This new flexibility extends far beyond basic TLS fingerprinting; it lets us quickly test and deploy security techniques that are oftentimes not feasible in the cloud. Whether it be a custom coturn 14 fork to log connections for WebRTC leaks without relying on client-side trust, mass network scans, or even logging custom DNS queries to track adversaries across multiple parts of the network stack.
A shrinking incumbent in the industry, Cint AB (CINT.ST), successfully turned billions into cents largely in part from a failure to execute in a rapidly evolving technology landscape. These measures are less to do with the security and fraud-detection needs of today, and more to do with ensuring reliable low-margin services for the Market Research respondent and online worker of tomorrow.
For suggestions on what subjects to cover first, please email me at max@generalresearch.com
MMFWCL,
– Max Nanis
- https://www.loudoun.gov/6188/Data-Centers-in-Loudoun-County ↩︎
- https://support.google.com/interconnect/answer/9058809?hl=en ↩︎
- https://www.nytimes.com/2010/12/03/nyregion/03building.html ↩︎
- https://www.nytimes.com/2003/08/24/realestate/commercial-property-after-blackout-independent-generators-are-generating.html ↩︎
- https://www.amd.com/en/newsroom/press-releases/2021-3-15-amd-epyc-7003-series-cpus-set-new-standard-as-hig.html ↩︎
- https://www.amazon.com/Solidigm-D7-D7-P5620-12-8-Internal/dp/B0DW4HNW16/ ↩︎
- https://www.servethehome.com/intel-fab-52-in-chandler-arizona-is-running-18a/ ↩︎
- https://www.bbc.com/news/articles/cgk28nj0lrjo ↩︎
- https://health.aws.amazon.com/health/status ↩︎
- https://www.wsj.com/business/telecom/africa-ip-addresses-china-3e543b9d ↩︎
- https://hindenburgresearch.com/equinix/ ↩︎
- https://www.eff.org/deeplinks/2023/08/isps-should-not-police-online-speech-no-matter-how-awful-it ↩︎
- http://ec2-reachability.amazonaws.com/ ↩︎
- https://github.com/coturn/coturn ↩︎